Bridging Legacy Data and AI: Making 30-Year-Old Insurance Data Accessible to AI Agents
If you've worked in insurance, you know that many brokerages run on systems built decades ago. Systems that contain invaluable customer data but weren't designed for modern integration needs. We built a prototype API to bridge 30-year-old PowerBroker FoxPro databases and modern AI agents.
Watch the demo in action on LinkedIn to see how this works in practice.
What We Built
Last week we built a prototype ASP.NET Core API to expose data stored in Broker Management Systems (BMS). We started with PowerBroker, but the architecture works with any BMS provided you have access to your data.
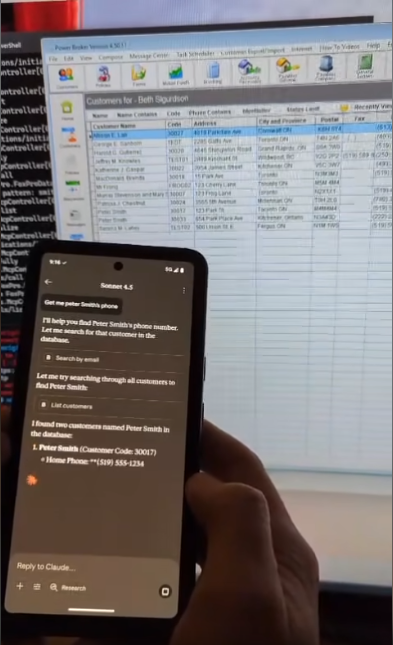
The API implements the Model Context Protocol (MCP), Anthropic's open standard for connecting AI assistants to data sources. With it, you can query legacy systems using AI agents like ChatGPT or Claude.
PowerBroker was released in 1992, and the underlying Visual FoxPro database technology was discontinued by Microsoft in 2007. Our goal was simple: make this 30+ year-old data available to AI agents released in 2025. We're pretty excited that we got it working as quickly as we did.
All 25,000+ fields across 356 tables are accessible through both MCP tools and RESTful endpoints.
And we managed to do it in real-time. Most people export to CSV files or duplicate the data into modern databases. We didn't. No exports. No syncs. No ETL pipelines. Just live data access through natural language.

The Real Challenges
The biggest challenges weren't architectural patterns - we know how to build clean APIs. The real problems were more practical:
- Learning the schema from scratch - 356 tables with 25,000+ fields and no documentation to guide us. We had to reverse engineer relationships and figure out which fields actually mattered.
- FoxPro's SQL dialect - It's not modern SQL. Parameterization works differently, joins have quirks, and you need to account for the oddities of a database system designed in the early 90s.
- Understanding MCP tooling - The Model Context Protocol was new to us. We had to learn how JSON-RPC 2.0 works, how to define tool schemas that AI agents can understand, and what makes a good tool versus one that just confuses the agent.
- Supporting multiple BMS systems from day one - We didn't want to build just a PowerBroker connector. The architecture needed to work with Sig, Epic, or any other BMS, provided we have access to the data. This meant the data provider pattern from the start.
- Development workflow - I wasn't about to abandon my Linux rig for Windows just to dev against FoxPro. Sure, I could spin up a Windows VM, but VMs are always slower. We needed a way to develop quickly without that overhead.
Our Solution: Pluggable Data Providers
As always, the solution is to pull apart the pieces. I mocked a CSV provider so I could dev quickly without access to a Foxpro db, and ensured we could swap between the two via config values:
- FoxProDataProvider: Connects to the actual PowerBroker database using 32-bit OleDB drivers (Windows-only)
- CsvDataProvider: Reads from CSV sample data for development and testing.
We switch on the provider via the config:
{
"DataProvider": {
"Type": "foxpro", // or "csv" for cross-platform development
"Csv": {
"DataDirectory": "./csv-data"
},
"FoxPro": {
"DataDirectory": "C:\\Path\\To\\PowerBroker\\Data"
}
}
}
This means developers can work on the API logic on any platform using sample CSV data, while production runs against the real database on Windows.
Layers of code
Layer 1: Data Access Abstraction
We defined clean interfaces for each data domain:
public interface ICustomerDataProvider
{
Task<Result<List<Customer>>> GetCustomersAsync();
Task<Result<Customer>> GetCustomerByCodeAsync(string customerCode);
Task<Result<List<Customer>>> SearchByEmailAsync(string email);
}
The FoxProDataProvider implementation uses OleDB to query DBF files, while CsvDataProvider reads structured CSV files. The rest of the application doesn't care which is used.
Layer 2: Business Logic as MCP Tools
Each queryable operation is implemented as an IMcpTool:
ListCustomersTool- Get all customersGetCustomerTool- Get specific customer by codeSearchByEmailTool- Search customers by emailGetNotesTool- Get customer interaction historyGetPoliciesTool/ListPoliciesTool- Query policy data
Each tool defines its JSON schema for the MCP protocol and executes queries via the data provider layer.
Layer 3: Dual Protocol Support
It's not enough to build the integration, we have to expose it in a sane way. Sometimes we want to query with an agent, other times we just want to pull a parameterized report from an API. Exposing the same DataProvider to both the RESTful API and the MCP services means we can use the same tools without more code.
- REST endpoints (
/customers,/notes,/policies) for traditional integrations and reporting tools - MCP endpoint (
/mcp) implementing JSON-RPC 2.0 for AI agent access
Now we can setup business logic once for both use cases.
What We Learned
1. Setting up MCP services is easy with good APIs
We were able to just layer the MCP service on top of our API without much hassle. Our API layer was well thought out and the few extra minutes of making sure the DataProvider was configured meant we could just expose those services to any interface we wanted.
Honestly, once the API layer and query logic was setup, hooking up to an AI Agent was minutes of effort.
2. Legacy Data Needs Context
A 30-year-old database doesn't document itself. I've heard great things about PowerBroker and their willingness to integrate, but we ran this experiment without them in our spare time. We created a SchemaReader utility to extract all 356 table schemas across the various DBF files. Once we had that data mapped and visualized, navigating the schema and querying out values became effortless. Even better, we could dump the entire schema map into an LLM and ask it to discover relationships we might have missed. On more than one occasion I asked "how do I join table X to table Y?" and the LLM just figured it out from our schema map.
3. Clean Architecture Pays Off
Despite working with legacy technology, we maintained clean separation of concerns:
- Dependency Injection for all components
- Repository pattern for data access
- Result pattern for error handling
- Interface segregation (separate interfaces per data domain)
This meant we could swap providers easily. Want to connect to Epic or SigXP instead of PowerBroker? Just write the queries that fill out the DataProvider interface.
But why?
I'm not a fan of rip and replace projects. Legacy systems supporting real businesses earned their place by solving real problems. PowerBroker has been running insurance brokerages since 1992. That kind of longevity means it works.
We don't need to replace the system. We just need access to the data.
Building an API layer that exposes legacy data gives us freedom to work with the data however we want. Want to use AI tooling today? Done. Want to integrate with modern BI platforms tomorrow? Easy. Want to build custom features next year without waiting for the BMS vendor to prioritize them? Now we can.
The legacy system keeps doing what it does best. We just get to build on top of it without being locked in.
Next Steps
I enjoyed this project. When I finally hooked up Claude and queried the data directly from PowerBroker, it was pretty exciting.
Next up is making regular BI reporting intuitive and easy. The APIs are already built so it should be pretty painless.
After that, we'll extend the query capabilities of both the API and the MCP tools. I understand that AI agents can get overwhelmed when you expose too many tools, so finding the right balance between comprehensive coverage and usability will be interesting.
If you're sitting on valuable data trapped in legacy systems, you don't need a massive modernization project to start leveraging AI or modern tooling. Sometimes all you need is a well-designed bridge.